- Published on
Decoding Large Scale Changes - An In-depth Look into Googles Software Engineering Practices
- Authors

- Name
- Leonard Vincent Simon Pahlke
- @leonardpahlke
This article is written in German and there is not a translation released
Large Scale Changes (LSC), hat in der Industrie vordergründig bei größeren Unternehmen große Bedeutung. Viele Unternehmen setzen sich mit diesem Thema auseinander oder sind sich möglicherweise nicht bewusst, dass sie indirekt damit konfrontiert werden. Google hat in einem Buch über Ihre Software-Engineering-Philosophie und Praktiken berichtet, wo ein Kapitel dem Thema „Large Scale Changes“ gewidmet[1]. Auch in der Wissenschaft wird das Thema betrachtet [2][3][4][5].
Dieser Text zielt darauf ab, eine umfassende Betrachtung von LSCs zu gewinnen, indem zunächst auf die Ansichten und Konzepte von Google eingegangen wird[1]. Weiterhin werden aktuelle Forschungen auf diesem Gebiet aufgezeigt.
Nach der Einführung folgt im zweiten Kapitel eine detaillierte Beschreibung von LSC, wobei vorwiegend auf das Buch „Software-Engineering“ von Google Bezug genommen wird[1]. Dabei werden die im Buch genannten Konzepte zusätzlich veranschaulicht. Im dritten Kapitel werden die Automatisierungen beschrieben, die bei Google in Bezug auf LSC zum Einsatz kommen. Es wird zudem bewertet, ob Automatisierungsstrategien sich lohnen zu implementieren, um mit LSCs zu verfahren. Im vierten Kapitel richtet sich der Blick auf aktuelle Forschungsarbeiten im Bereich LSC, insbesondere im Zusammenhang mit Machine Learning. Abschließend werden in Kapitel fünf die wichtigsten Erkenntnisse dieser Arbeit zusammengefasst und ein Ausblick auf zukünftige Entwicklungen und Potenziale im Bereich LSC gegeben.
Large Scale Changes (LSC)
In diesem Kapitel wird LSC eingeordnet, dabei wird sich primär auf das Buch „Software-Engineering at Google“ bezogen[1]. Ein weiterer Schwerpunkt liegt auf atomaren Änderungen in der Softwareentwicklung und den Ursachen, die wiedderum zu LSC führen.
LSC beschäftigen sich mit Änderungen, die in Softwareprojekten vorgenommen werden. Es lassen sich Änderungen in der Softwareentwicklung in verschiedene Kategorien einteilen.
- Fehlerbehebung (Bugfixes), bestehende Fehler im Code identifizieren und korrigieren, um die Stabilität und Funktionalität der Software zu gewährleisten.
- Feature-Entwicklung (Feature Development), neue Funktionalitäten oder Erweiterungen implementierem, um den Nutzen und die Vielseitigkeit der Software zu verbessern.
- Überarbeitung (Refactoring), der Code oder die Architektur der Software wird optimiert oder neu strukturiert, um eine bessere Wartbarkeit, Lesbarkeit und Effizienz zu erreichen.
- Dokumentation (Documentation), die Aktualisierung oder Erstellung von Dokumentationen, um Entwicklern und Anwendern einen umfassenden Einblick in den Code und die Funktionen der Software zu geben.
Änderungen an Softwareprojekten wurden schon immer durchgeführt. Allerdings hat sich die Softwareentwicklung im Laufe der Zeit stark verändert und damit auch der elementare Prozess, Änderungen an einem Softwareprojekt vorzunehmen. Diese Auswirkungen sind auch in anderen Bereichen der Informatik zu beobachten, wie im Bereich Big Data. Daten wurden schon immer zwischen IT-Systemen ausgetauscht, aber die heutigen Rahmenbedingungen in der Industrie führen dazu, dass enorme Datenströme verarbeitet werden müssen, die den Bereich Big Data hervorgebracht haben, in dem neue Methoden und Praktiken zur Anwendung kommen. Auch die Rahmenbedingungen für Änderungen im Softwareentwicklungsprozess haben sich geändert.
Im nächsten Abschnitt wird in LSC eingeführt und Beispiele genannt, die das Konzept verdeutlichen, bevor auf atomare Änderungen und die Relevanz und Barrieren von LSCs weiter angegangen wird.
Einführung in Large Scale Changes (LSC)
Google definiert LSC als eine Menge von Änderungen, die logisch zusammenhängen, aber praktisch nicht als eine einzige atomare Einheit eingereicht werden können. Auf diese Definition wird zum Ende dieses Abschnitts eingegangen.
LSCs treten in großen Projekten oder in einem System zwischen gekoppelten Projekten auf. Bei LSCs führt eine Änderungsursache, wie z.B. API-Verwaltungen, zu einer erheblichen Anzahl von Anpassungen im Projekt. Schwierig wird es, wenn die Änderung nicht einfach als Einheit committet werden kann und aufgeteilt werden muss. In diesem Fall wird eine LSC bearbeitet.
Die Relevanz von LSCs, die Faktoren, die bei LSCs eine Rolle spielen, und die Barrieren, die LSCs herausfordernd machen, werden in den folgenden Abschnitten diskutiert. Die nachstehende Liste enthält Beispiele, die zu LSCs führen können.
- Aufräumen von Bibliotheksverwaltungen: Wenn Frameworks bspw. eine neue Version erhalten, hat diese Änderung eine erhebliche Auswirkung auf das eigene Projekt und kann zu einem LSC führen.
- Migration zu neuen API-Versionen: Wenn eine neue Version einer externen API veröffentlicht wird, kann dies zu einem LSC führen.
- Veraltete eigene APIs: Wenn in einem System APIs deprecated werden, kann dies zu einem LSC führen.
Es gibt weitere Ursachen, jedoch wird deutlich, dass aufgelistete Änderungen nicht ungewöhnlich sind und regelmäßig auftreten. Die Häufigkeit von LSCs wird von der Projekttopologie beeinflusst. Es wird zudem deutlich, dass LSC nicht klar, schwarz weiß, identifizierbar sind und der Übergang fließend sein kann. Die am Anfang genannte Definition von Google, die darauf abzieht, dass bei LSC Änderungen nicht als atomare Änderungen ausgerollt werden können, hilft als Daumenregel.
Atomare Änderungen
Atomare Änderungen in der Softwareentwicklung beziehen sich auf den Ansatz, Änderungen am Quellcode in kleinste, unteilbare Einheiten aufzuteilen. Bei atomaren Änderungen handelt es sich um einzelne und abgeschlossene Aktualisierungen, die unabhängig voneinander funktionieren und getestet werden können. Eine atomare Änderung ist eine Änderung, die auf Komponenten oder Schnittstellen angewendet wird und nicht in kleinere Änderungen zerlegt werden kann.[6]
In den folgenden Unterabschnitten werden zunächst die Bedeutung von atomare Änderungen erläutert. Weiterhin werden Barrieren identifiziert, die dazu führen, dass nicht ausschließlich atomare Änderungen in einem Software-Projekt durchgeführt werden können.
Relevanz von atomaren Änderungen
Atomare Änderungen in der Softwareentwicklung ermöglichen kontrollierte und gut verständliche Anpassungen am Code, ohne die Gesamtintegrität des Systems zu gefährden[1][6]. Sie bieten verschiedene Vorteile:
- Testen: Atomare Änderungen können leicht isoliert und getestet werden, um gewünschte Ergebnisse zu erzielen und unerwartete Nebenwirkungen zu vermeiden.
- Prüfung von Änderungen: Durch die Aufteilung in atomare Einheiten lässt sich die Codequalität einfacher überprüfen und sicherstellen, dass Standards und bewährte Vorgehensweisen eingehalten werden.
- Zuweisung von Reviewern: Atomare Änderungen erleichtern die Zuweisung von Reviewern, da sie sich auf spezifische Codeausschnitte konzentrieren können, anstatt komplexe Änderungen zu bewerten.
- Rückgängigmachen: Bei Bedarf können atomare Änderungen aufgrund der Übersichtlichkeit und vorhersehbaren Auswirkungen leicht rückgängig gemacht werden, falls sie den Erwartungen nicht entsprechen oder unvorhergesehene Probleme auftreten.
Die Verwendung atomarer Änderungen fördert eine bessere Teamarbeit, da sie die Nachvollziehbarkeit, Testbarkeit und Wartbarkeit des Codes verbessern. Sie ermöglichen eine bessere Kontrolle des Entwicklungsprozesses und eine schnellere Bereitstellung neuer Funktionen. Es gibt jedoch Situationen, in denen atomare Änderungen nicht immer durchgeführt werden können.
Barrieren von atomaren Änderungen
Es gibt verschiedene Barrieren, die die Durchführung von atomaren Änderungen in der Softwareentwicklung beeinträchtigen können. Folgende Gründe dafür verantwortlich sein[1][6].
- Technische Einschränkungen: Bestimmte technische Faktoren können die Aufteilung von Änderungen in atomare Einheiten erschweren. Beispielsweise hat das Version Control System (VCS) Beschränkungen, wie viele Daten maximal in einer Änderung verändert werden können.
- Merge Konflikte: Bei paralleler Code-Entwicklung und Zusammenführung können Konflikte auftreten, die eine reibungslose Integration von Änderungen behindern können. Besonders in größeren Teams oder Projekten mit vielen gleichzeitigen Änderungen können Merge-Konflikte auftreten.
- „Haunted Graveyards“: „Haunted Graveyards“ sind undokumentierte oder schwer verständliche Codebereiche oder Funktionen mit unklaren Abhängigkeiten. Änderungen in solchen Bereichen können unerwartete Konsequenzen haben und erfordern eine umfassende Analyse und Überarbeitung.
- Heterogenität: In komplexen Softwareprojekten mit verschiedenen Plattformen, Technologien und Entwicklungsstilen kann die Aufteilung von Änderungen in atomare Einheiten schwierig sein. Die Harmonisierung und Koordination zwischen den verschiedenen Komponenten oder Teams kann herausfordernd sein.
Die Durchführung atomarer Änderungen ist wünschenswert und erleichtert den Entwicklungsfluss in der Softwareentwicklung. Dennoch, wie gezeigt, ist es nicht immer möglich, atomare Änderungen durchzuführen. LSC entstehen, wenn atomare Änderungen nicht durchgeführt werden können.
Relevanz von Large Scale Changes (LSC)
Die Durchführung von LSC in einem Softwareprojekt wird durch bestimmte Vektoren beeinflusst. In der nachfolgenden Fig. 1 sind die Vektoren aufgeführt, die von Google, explizit sowie implizit, benannt wurden[1].
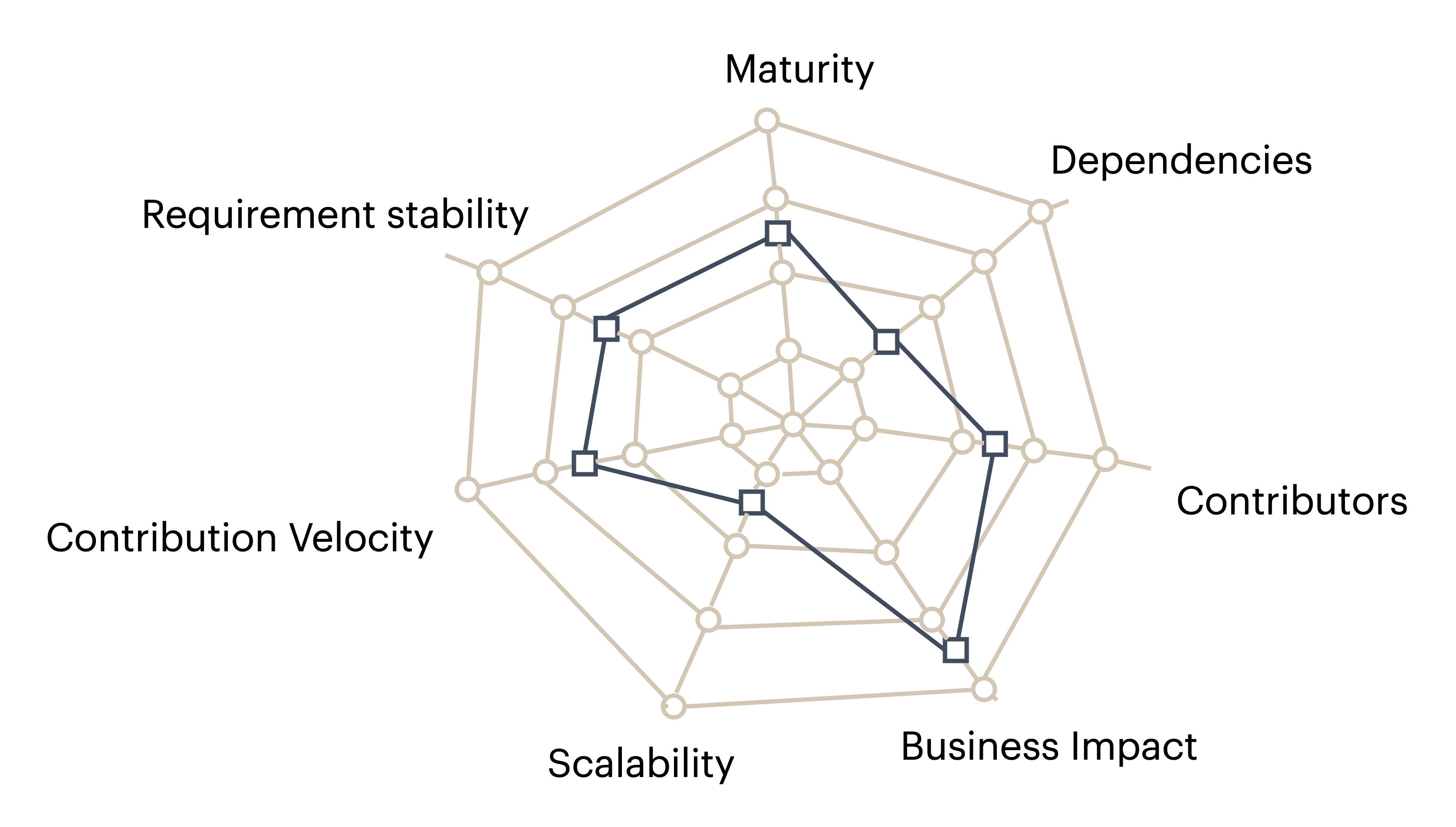 Fig 1: Vektoren, die LSC begünstigen
Fig 1: Vektoren, die LSC begünstigenDie Fig. 1 zeigt ein Spinnennetz-Diagramm, das verdeutlicht, um so größer die Fläche des Spinnennetzes ist, umso wahrscheinlicher treten LSC ein. Die Vektoren müssen für einen Kontext spezifiziert werden, in dem LSC evaluiert werden sollen. In der nachfolgenden Liste werden die im Diagramm dargestellten Vektoren umschrieben.
- Reife (Maturity): In welchem Maße ist das Softwareprodukt fortgeschritten? Sind mittlerweile nicht mehr die ursprünglichen Autoren daran beteiligt, läuft es jedoch weiterhin reibungslos?
- Anforderungsstabilität (Requirements Stability): Wie stabil sind die Anforderungen an die Software? Befindet sich die Software in einem instabilen Umfeld mit schnellen, störenden externen Einflüssen?
- Abhängigkeiten (Dependencies): Hat die entwickelte Software viele Abhängigkeiten? Wie häufig ändern sich diese Abhängigkeiten? Ist die Qualität der Abhängigkeiten bekannt und einsehbar? Wie oft müssen Abhängigkeiten aktualisiert werden?
- Mitwirkende (Contributors): Wie viele Personen sind durchschnittlich an der Software beteiligt?
- Skalierbarkeit (Scalability): Verändert sich die Anzahl der Personen, die an dem Projekt arbeiten? Wie häufig ändern sich Teams und deren Expertise?
- Geschäftsauswirkung (Business Impact): Wie relevant ist die Software für das Unternehmen? Welche Auswirkungen hätte ein Ausfall dieser Software? Muss die Software kontinuierlich verfügbar sein?
- Beitragsgeschwindigkeit (Contribution Velocity): Wie intensiv wird an der Software gearbeitet? Werden häufig Änderungen am Softwareprojekt vorgenommen? Welche Gründe liegen diesen Änderungen zugrunde? Gibt es verschiedene Bereiche, in denen gearbeitet wird?
Die beschriebenen Vektoren in der Fig. 1 sind nicht heuristisch spezifiziert, sondern umschrieben. Um eine genaue Bewertung vornehmen zu können, muss eine Heuristik entwickelt werden. Es ist jedoch ersichtlich, dass verschiedene technische und organisatorische Ursachen zur Förderung von LSC beitragen.
Herausforderungen von Large Scale Changes (LSC)
Es gibt eine Reihe von Herausforderungen mit dem Umgang von LSC. In der nachfolgenden Liste sind diese aufgelistet[1].
- Große Anzahl an Änderungen: LSCs führen zu umfangreichen Code-Anpassungen, die mit Risiken verbunden sind und viel Arbeit erfordern.
- Monotone Arbeit: LSCs aktualisieren eine bestimmte Art von Änderung, wie z. B. das Entfernen einer Methode, in vielen ähnlichen Szenarien im Code. Diese wiederholten, aber weitreichenden Arbeiten sind gefährlich für die Codebasis.
- Team übergreifende Prozesse: LSCs übergreifen Entwicklerteams, die gleichermaßen von dem LSC betroffen sind. Die Koordinierung über Teams hinweg ist eine Herausforderung.
- Testen: Das Testen von LSC ist herausfordert, da zum einen die übergreifende Änderung des LSC getestet werden muss und zugleich die einzelnen Änderungen, die erstellt wurden, um die LSC Änderung zuzuführen
- Code-Überprüfung: Die Code-Überprüfung ist eine Herausforderung, da sowohl projektbereichsspezifische Experten als auch Experten für die gesamte Codebasis konsultiert werden müssen. Die Koordination der Überprüfungen stellt ebenfalls eine Herausforderung dar.
- LSC Ownership: Die Suche nach einem Eigentümer des LSC kann herausfordernd sein, da diese Änderungen das gesamte Repository oder sogar mehrere Repositorys betreffen. Es ist schwierig, jemanden zu finden, der die gesamte Situation überblicken kann.
In dem nächsten Abschnitt, Automatisierung von Large Scale Changes, werden diese Herausforderungen aufgegriffen und beschrieben, wie Google mit diesen umgeht.
Automatisierung von Large Scale Changes bei Google
Dieses Kapitel behandelt die automatisierte Behandlung von LSCs. Zunächst wird untersucht, in welchen Fällen es sinnvoll ist, Automatisierungen einzusetzen, und ob die Rahmenbedingungen für die Automatisierung von LSCs gegeben sind. Anschließend wird die von Google entwickelte Strategie zur Bewältigung von LSCs betrachtet. Im nachfolgenden Kapitel werden aktuelle Forschungsarbeiten im Bereich LSC beleuchtet, die ebenfalls das Thema Automatisierung betreffen.
Evaluierung zur Automatisierung von Prozessen im Zusammenhang mit Large Scale Changes
Die Entscheidung, einen Prozess zu automatisieren, sollte sorgfältig abgewogen werden, da nicht jeder Prozess gleichermaßen von Automatisierung profitiert. Der Aufwand für die Entwicklung der Automatisierung muss in Relation zum erwarteten Nutzen betrachtet werden, um eine fundierte Entscheidung zu treffen. Eine Reihe von Parametern, werden herangezogen, um festzustellen, ob eine Automatisierung sich lohnt[7]. Diese Parameter werden im folgenden Abschnitt ausführlich erörtert, um zu bestimmen, ob es sich lohnt automatisierte Tools oder ganze Systeme zu entwickeln, um mit LSCs einfacher zu verfahren.
- Hoher Zeitaufwand: LSCs erfordern aufgrund einer großen Anzahl individueller Änderungen einen erheblichen Zeitaufwand.
- Häufige Wiederholungen: LSCs können regelmäßig auftreten. Wie im vorherigen Kapitel beschrieben, gibt es verschiedene Faktoren, die zu LSCs führen können, und die Häufigkeit variiert von Projekt zu Projekt. Es wurde festgestellt, dass LSCs nicht vollständig vermieden werden können.
- Große Datenmengen: LSCs beinhalten umfangreiche Änderungen in Softwareprojekten und erfordern daher die Anpassung großer Datenmengen.
- Monotone oder gefährliche Aufgaben: Wie bereits im vorherigen Kapitel erwähnt wurde, resultieren die Ursachen von LSCs oft aus einer Vielzahl monotoner Änderungen.
- Skalierbarkeit: Die Skalierung der Unternehmens-IT-Infrastruktur ist unternehmensspezifisch und kann nicht pauschal, abstrahiert bewertet werden. Es ist daher notwendig, den konkreten Fall zu analysieren.
- Kosteneinsparungen: Je nach Häufigkeit von LSCs in einem Projekt kann es sich lohnen, Automatisierung einzusetzen, um Kosten zu sparen.
Eine Automatisierung von LSCs lohnt sich. Bei kleineren Projekten kann jedoch der Nutzen der Automatisierung möglicherweise noch nicht den Aufwand rechtfertigen, und die Einführung entsprechender Tools kann zu einem späteren Zeitpunkt sinnvoll sein.
LSC Automatisierungsstrategie von Google
Bei Google ist deren LSC-System ein wichtiger Bestandteil in deren Softwareentwicklung. Google nennt deren System Rosie und beinhaltet Fähigkeiten, um Benachrichtigungen an Entwickler zu verschicken, die durchzuführende Änderungen in Teile (Shards) zu unterteilen, Reviewer für einzelne Shards zuzuweisen, Änderungen einzelner Shards zu testen und zu committen. Die nachfolgende Abbildung ist aus Beschreibung erschlossen zeigt, gibt einen Überblick über das System[1].
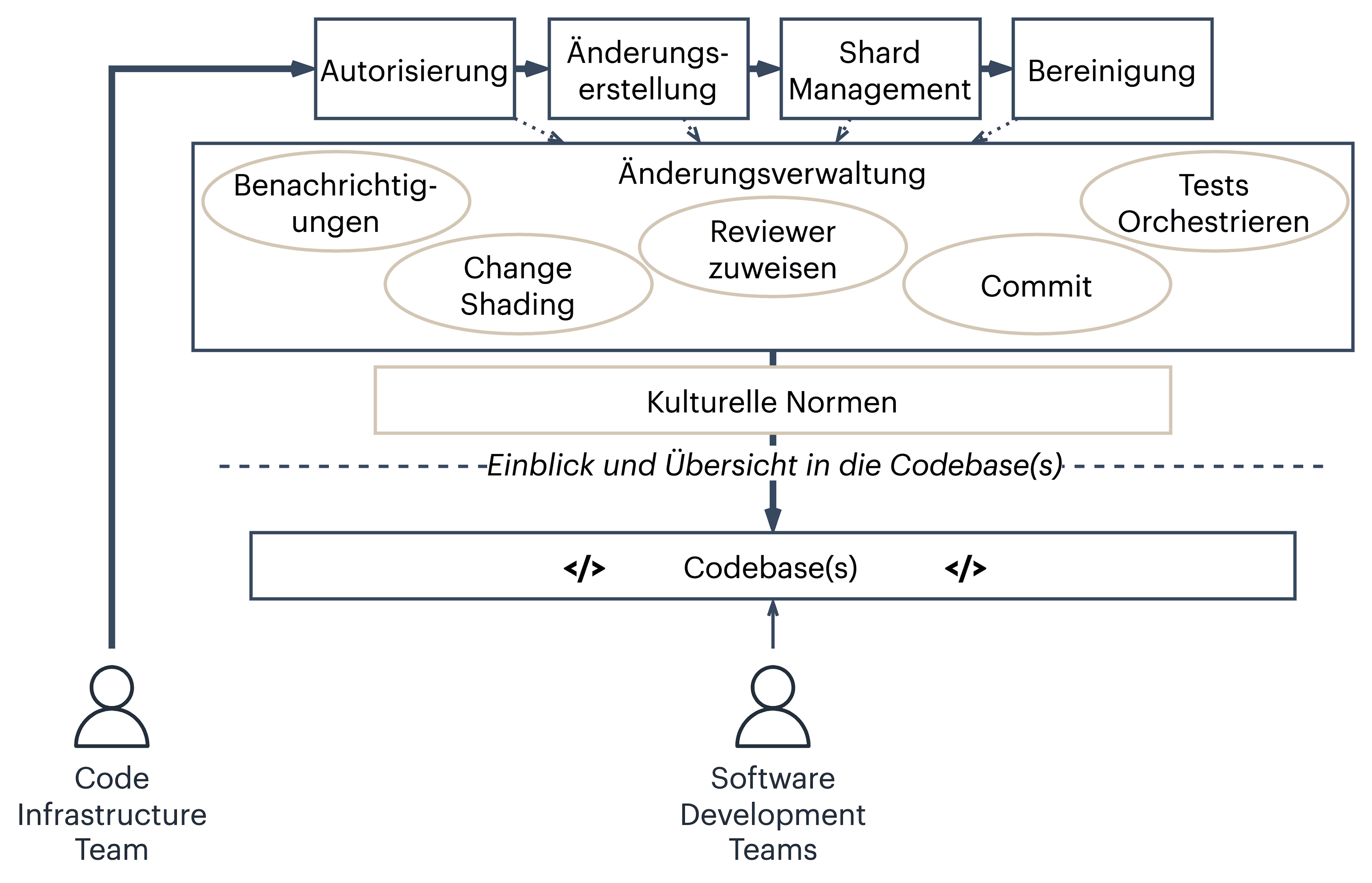 Fig 2: Google LSC Automatisierungsstrategie: Rosie
Fig 2: Google LSC Automatisierungsstrategie: RosieWie in der Fig. 2 dargestellt ist, sind nicht die einzelnen Entwicklerteams verantwortlich LCS durchzuführen, sondern ein Infrastruktur-Team. Das Infrastruktur-Team kennt sich mit der Verwaltung von LSC aus, und da LSC mehrere Teams übergreifen und von der Repository Topologie abhängig sind, hat sich gezeigt, dass ein dediziertes Infrastrukturteam am besten geeignet ist. Wenn ein LSC erstellt wird, werden die folgenden Schritte durchgeführt.
- Autorisierung (Authorization): Ein Dokument wird ausgefüllt, um die Änderung durchführen zu können. In dem Dokument wird primär die Auswirkung des LSCs diskutiert. Die meisten LSCs folgen einem ähnlichen. Muster und die Autorisierung ist daher unproblematisch.
- Änderungserstellung (Change Creation): Der LSC Autor erstellt die Änderung und greift dabei auf Tools zurück.
- Shard Management (Sharding): Wurde die Änderung eingereicht, so wird diese in Shards unterteilt, Benachrichtigungen herausgeschickt, Reviewer zugewiesen und Tests durchgeführt. Reviewer sind in Teilbereichen über „OWNERFILES“ spezifiziert.
- Bereinigung (Cleanup): Nachdem die Änderungen reviewt wurden, werden die Shards nacheinander committet und der LSC ist somit behandelt.
Es wird deutliche, dass das System umfangreich ist und nicht trivial nebenbei entwickelt werden kann, sondern die Aufmerksamkeit eines Entwicklerteams benötigt.
Machine Learning gestützte Prozesse in der Verwaltung von Large Scale Changes
Der Bereich Machine Learning wurde in den vergangenen Jahren erheblich Fortschritte erzielt und damit neue Möglichkeiten eröffnet, bestehende Prozessautomatisierungen auszuarbeiten und neue Anwendungsfälle zu automatisieren[8][9]. In der Fig. 3 ist dargestellt, wie ML basierende Tools in Forschungsarbeiten genannt wurden, die Source Code Analysen durchführen. Eine Untermenge dieser Tools könnte in den zuvor beschriebenen Automatisierungsprozessen um LSC eingesetzt werden. In der nachfolgenden Fig.4 wird exemplarisch der Aufbau eines Machine Learning Systems gezeigt, das verwendet wird, um Code Reviews zu erstellen.
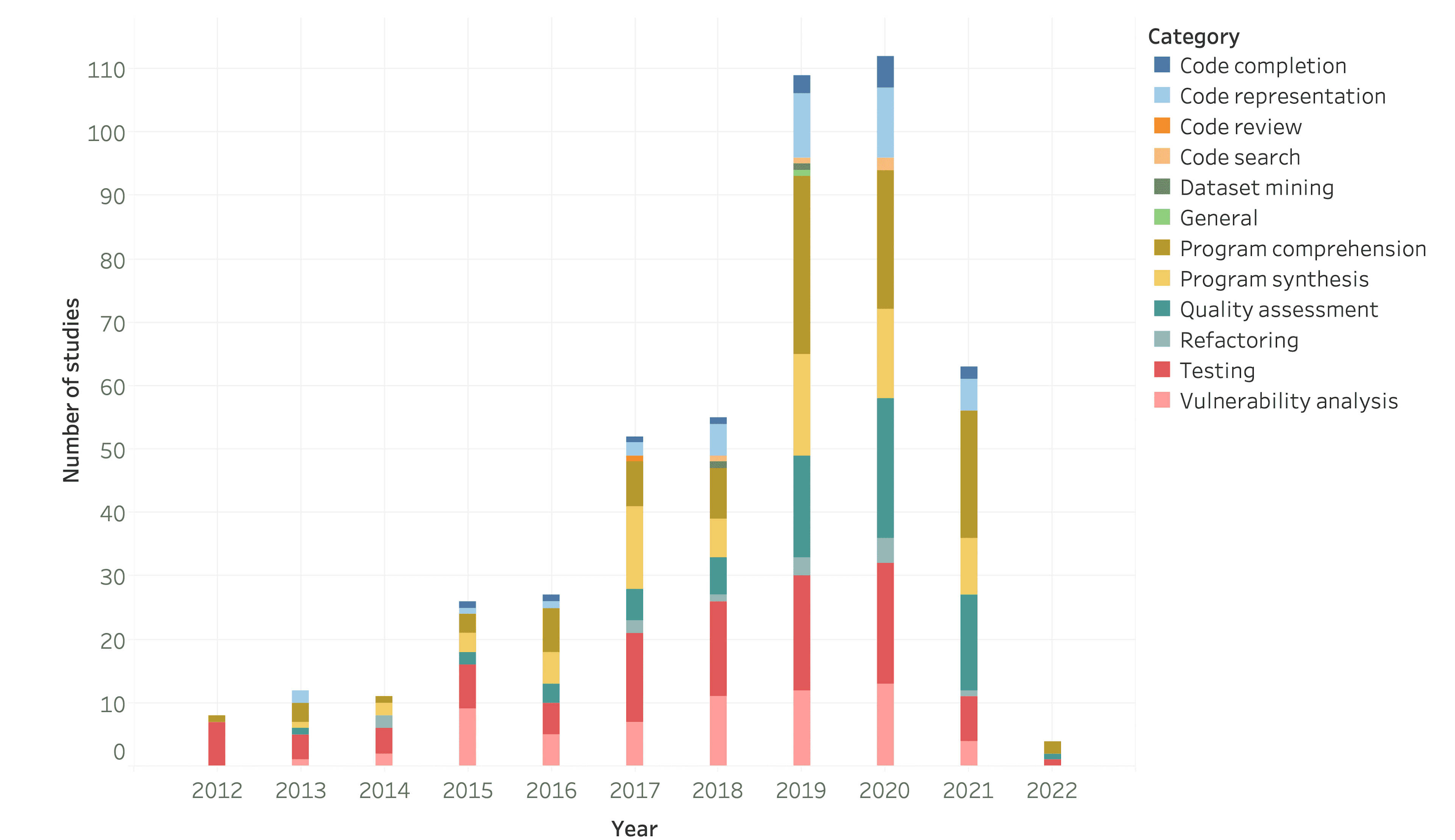 Fig 3: Kategorisierung von ML-fähigen Quellcode-Analyseaufgaben[8]
Fig 3: Kategorisierung von ML-fähigen Quellcode-Analyseaufgaben[8]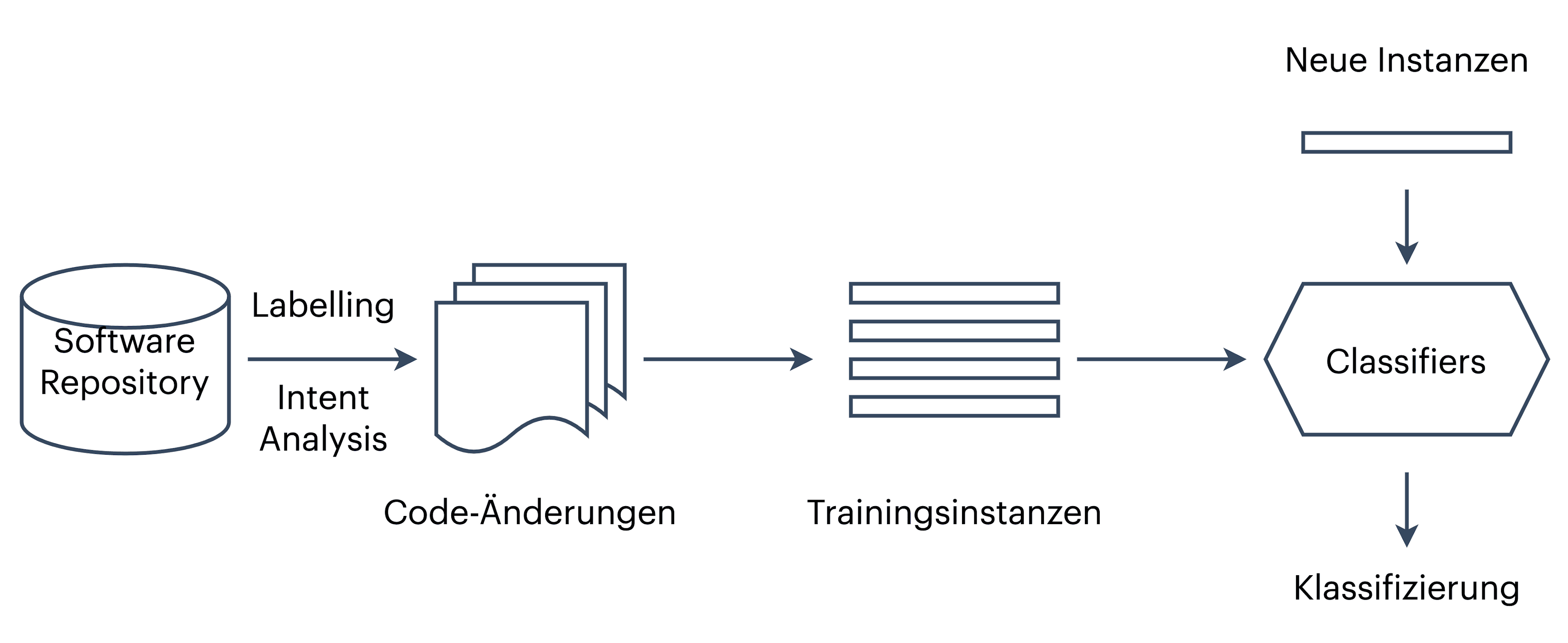 Fig 4: ML Model zum Erstellen von Code Reviews
Fig 4: ML Model zum Erstellen von Code ReviewsDank der Vielzahl an Open-Source-Projekten, die industrieweit eingesetzt werden und hohen Standards entsprechen, gibt es reichhaltig Daten. Das Machine Learning Modell in der Figure nutzt Daten von durchgeführten Code-Änderungen und verarbeitet diese in Trainingsinstanzen. Der trainierte Klassifizierer wird in den Software Entwicklungsprozess eingebettet.
Zusammenfassung und Ausblick
Large Scale Changes (LSC) ist ein interessanter Bereich in der Softwareentwicklung. Google zeigt, wie wichtig es ist, Prozesse und Automatisierung einzuführen, um mit LSCs umzugehen. LSCs betreffen alle Softwareprojekte, jedoch gibt es bestimmte Faktoren, die solche Änderungen begünstigen. Es wäre hilfreich, diese Faktoren zu bestimmen und eine Heuristik zu entwickeln, um ein besseres Verständnis für LSC zu erlangen und entsprechende Strategien für Unternehmen zu entwickeln, mit diesen umzugehen. Die von Google beschriebene Automatisierung zeigt eine umfassende Verwaltung von LSC, die als Referenz für unternehmensspezifische Initiativen herangezogen kann. Durch den Einsatz von maschinellem Lernen ergeben sich Möglichkeiten, die Automatisierung von LSCs auszubauen.
- [1] T. Winters, T. Manshreck, and H. Wright, Software engineering at google: Lessons learned from programming over time. O’Reilly Media, 2020.
- [2] D. E. Perry, H. P. Siy, and L. G. Votta, “Parallel changes in large-scale software development: An observational case study,” ACM Trans. Softw. Eng. Methodol., vol. 10, p. 308–337, jul 2001.
- [3] P. Ebraert, J. Vallejos, P. Costanza, E. Van Paesschen, and T. D’Hondt, “Change-oriented software engineering,” in Proceedings of the 2007 International Conference on Dynamic Languages: In Conjunction with the 15th International Smalltalk Joint Conference 2007, ICDL ’07, (New York, NY, USA), p. 3–24, Association for Computing Machinery, 2007.
- [4] M. M. Lehman and L. A. Belady, Program evolution: processes of software change. Academic Press Professional, Inc., 1985.
- [5] R. Selby, “Enabling reuse-based software development of large-scale systems,” IEEE Transactions on Software Engineering, vol. 31, no. 6, pp. 495–510, 2005.
- [6] T. Feng and J. I. Maletic, “Applying dynamic change impact analysis in component-based architecture design,” in Seventh ACIS International Conference on Software Engineering, Artificial Intelligence, Networking, and Parallel/Distributed Computing (SNPD’06), pp. 43–48, IEEE, 2006.
- [7] W. Tan, W. Shen, L. Xu, B. Zhou, and L. Li, “A business process intel- ligence system for enterprise process performance management,” IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), vol. 38, no. 6, pp. 745–756, 2008.
- [8] T. Sharma, M. Kechagia, S. Georgiou, R. Tiwari, I. Vats, H. Moazen, and F. Sarro, “A survey on machine learning techniques for source code analysis,” arXiv preprint arXiv:2110.09610, 2021.
- [9] L. Jonsson, M. Borg, D. Broman, K. Sandahl, S. Eldh, and P. Rune- son, “Automated bug assignment: Ensemble-based machine learning in large scale industrial contexts,” Empirical Software Engineering, vol. 21, pp. 1533–1578, 2016.