- Published on
Navigating the Landscape of APIs for Energy Measurement in the Cloud
- Authors

- Name
- Leonard Vincent Simon Pahlke
- @leonardpahlke
This is the second of three blogs in the series "Unlock Energy Consumption in the Cloud with eBPF". The previous blog can be found here.
Measuring the energy consumption of your system is not a trivial endeavor, especially when it comes to the cloud. In the cloud, we usually manage a complex infrastructure with all kinds of heterogeneous services that are managed by different parties, which makes all of this so much more challenging. In this blog, we will not explore the organizational or management challenges that come with this, but rather focus on how this can technically be approached today.
We're all familiar with electric power, but it's something we don't often deal with in software engineering. Energy is consumed by hardware components in order to toggle transistors, the fundamental switches of electronic devices. Simply put, less energy is needed when fewer transistors are turned on, and more energy is needed when more transistors are switched on and off. It is a bit more complicated than this, since it is also about how switches are used and not just about the number of switches available. However, that is outside the scope of this blog.
From year to year, we see smaller chip sizes being released with smaller transistors, moving towards more compact nanometer sizes. This reduction in size implies that a greater number of transistors can be utilized within a given energy budget, theoretically enabling enhancements in performance without corresponding increases in energy consumption. Yet this evolution also brings new challenges, such as managing heat output and the quantum mechanical effects that become significant at such small scales. We won't go into these here.
Software engineering emphasizes on building layers of abstraction. That is also the case with abstracting raw hardware, resulting in no direct access to transistors. This separation is advantageous because it allows software developers to focus on functionality and user experience without having to worry about hardware operations. Because of this, precise energy measurement can only be done with direct hardware support, like using IoT devices that are placed between the computing resources and the energy source. Without hardware support, software-based methods for estimating energy consumption will have to rely on approximations. Given these constraints, how can we effectively measure energy within the complex landscape of cloud computing?
Measuring Energy Consumption — Moving Abstraction Layers
At the hardware level, manufacturers provide APIs for broader system management, including energy usage monitoring features, in compliance with industry standards like IPMI (Intelligent Platform Management Interface). Linux and other operating systems (OS) are responsible for mediating between application requirements and hardware capabilities. Making the best use of the available hardware resources requires the OS to set the correct CPU frequency, enable and disable cores, and put hardware components into on, off, sleep or idle states. This affects systems energy consumption. Linux provides interfaces, such as the /sys/ file system, that user applications can access to manage energy settings and request low-power modes. At the next level, user applications can record these metrics and compare them with other system data, such as CPU usage or process information, which can enrich the data collected. We know more about the software we use at the user level than we do at the hardware or operating system level, which lets us add semantic metadata to the data. If we continue to move up the stack, we will deal with a distributed cloud system that is about energy management. Each node has monitoring agents that collect energy metrics and send them back for central analysis. At the cluster level, it is possible to enhance the data gathered by incorporating knowledge of the infrastructure's topology and inter-node communication patterns.
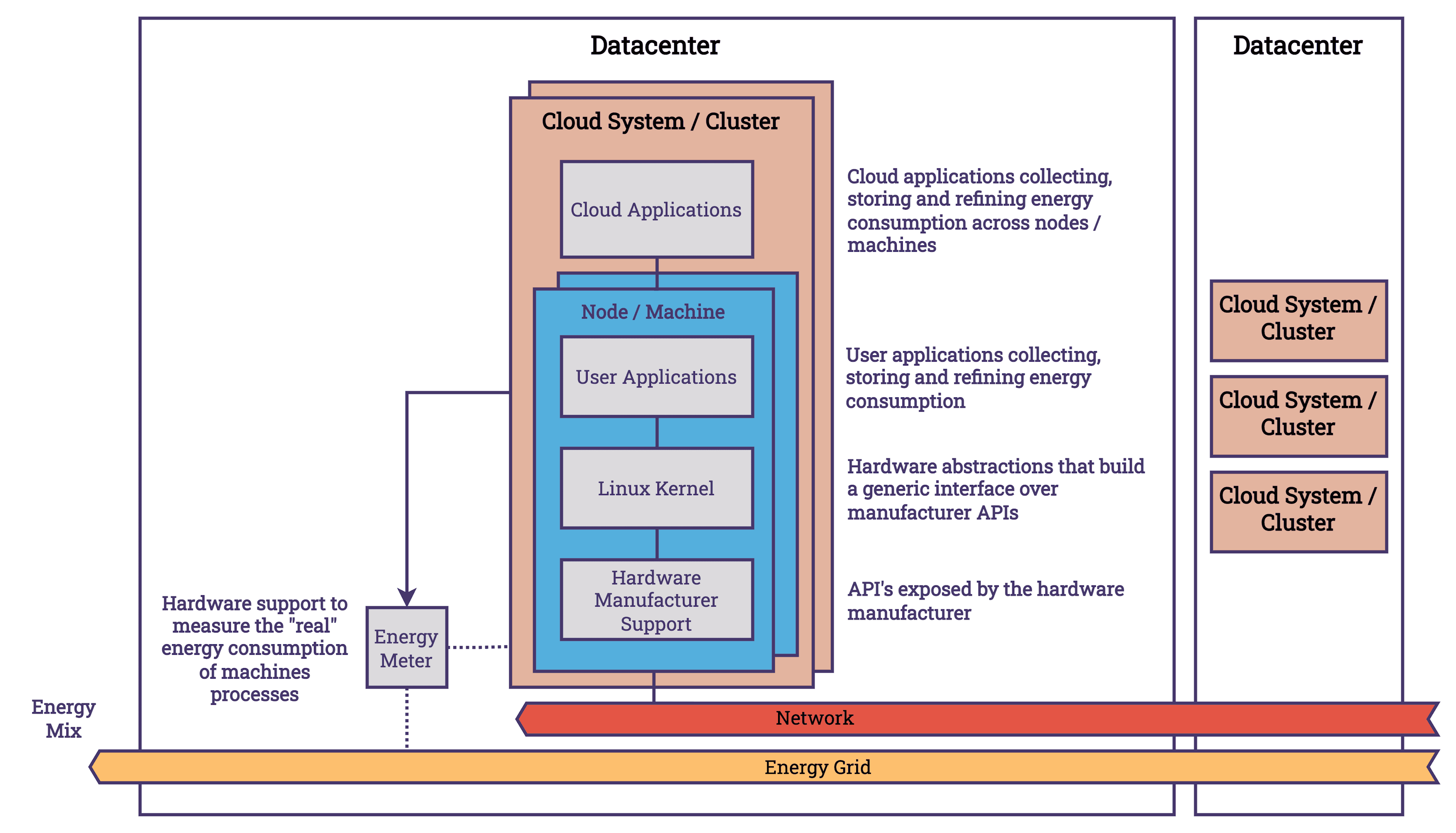
A simplified overview of the key abstraction layers involved in measuring energy use within cloud computing can be found in the diagram. It serves as a reminder of the importance of separating concerns and its impact on aggregating energy consumption across various levels. Despite the fact that these abstractions present challenges in accessing data, owing to the necessity of coordinating multiple components and vendors, they also facilitate the level of sophistication and complexity required for further innovation. The presence of these layers facilitates the creation of solutions that are both more efficient and effective. Let’s take a look at each layer and how they connect to each other.
Hardware / Chip manufactures
Among chip architecture, different energy measurement APIs exist. Let’s take a look.
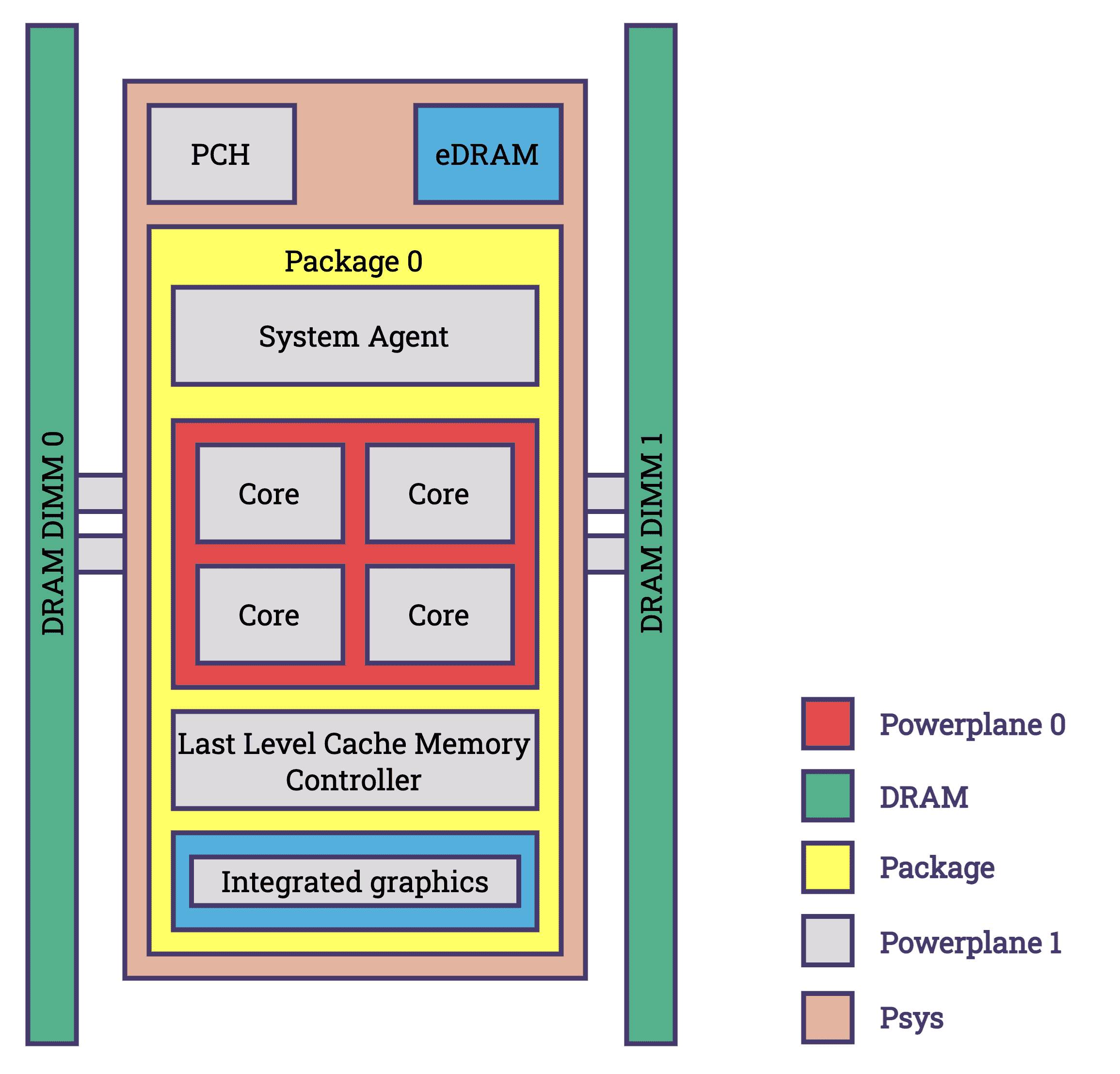
- Intel: Intel's chips have included the Running Average Power Limit (RAPL) feature starting with the Sandy Bridge architecture in 2011. Initially designed to enable BIOS and operating systems to set virtual power limits, RAPL also facilitates the measurement of energy consumption. Over subsequent iterations, RAPL has expanded to encompass a broader range of energy-drawing components across various packages. Components covered by RAPL are shown in the diagram below. RAPL provides precise energy consumption measurements with a minimal margin of error [source].
Power domains supported by RAPL [source]
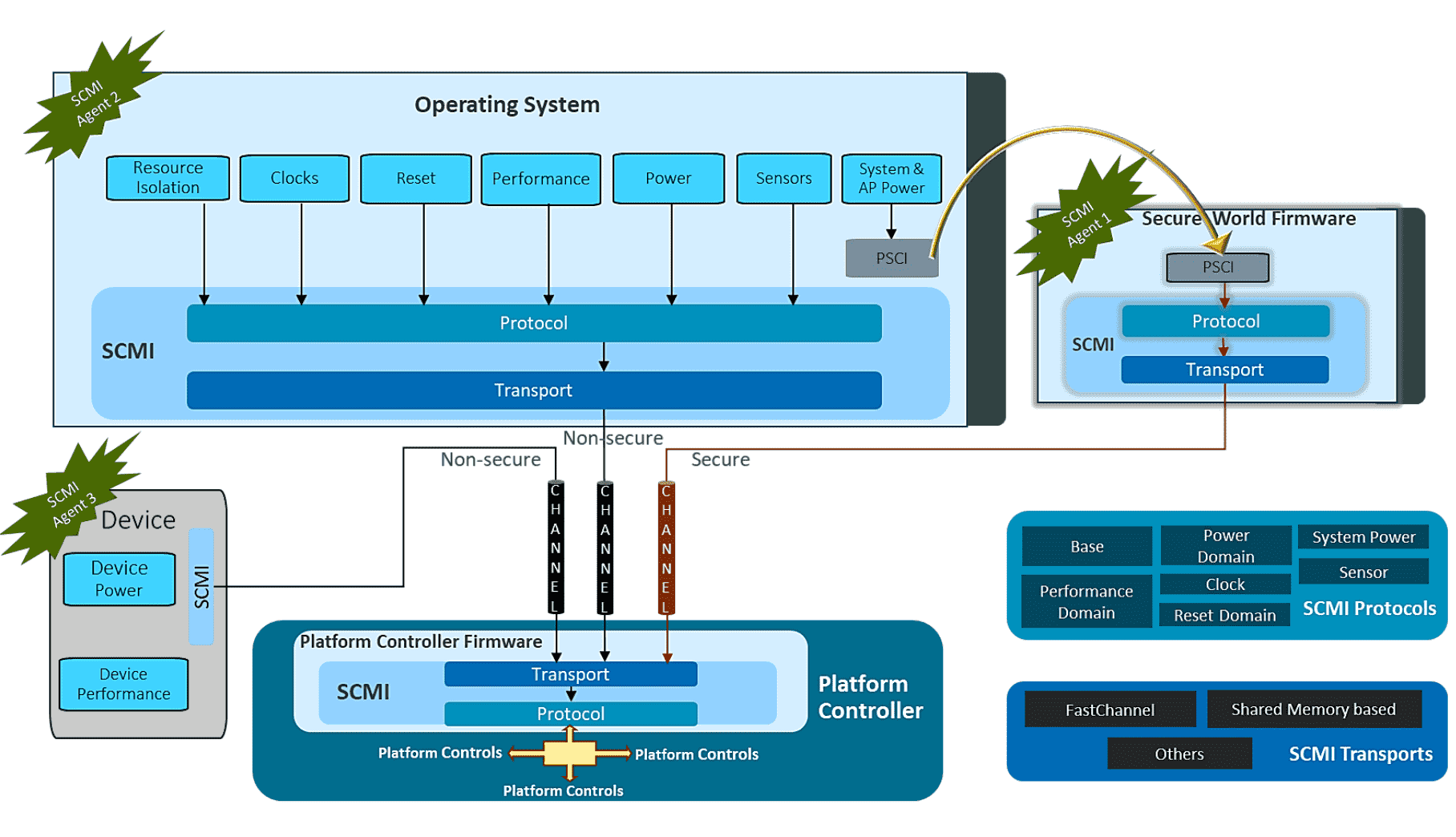
- ARM: ARM is unique in that it designs the architecture for system-on-a-chip configurations, which integrate components such as the CPU, DRAM, and storage. ARM does not build these chips itself, but licenses the designs to manufacturers such as Qualcomm. As a result, variations among chips, including differences in power measurement capabilities, exist. ARM has introduced the System Control and Management Interface (SCMI), which allows manufacturers of ARM chips to report energy metrics, among other metrics [documentation].
- AMD: AMD's approach aligns with Intel's, incorporating power tracking into its chipsets through an API similar to RAPL called APML (Advanced Platform Management Link), enhancing its ability to monitor power use, particularly in energy-sensitive mobile and IoT devices (see handbook. AMD also builds Kernel drivers to report in RAPL, see
amd_energy). - NVIDIA: NVIDIA offers with the System Management Interface (SMI), a command-line based tool that enables tracking and adjustment of various GPU parameters, including power consumption [documentation]. NVIDIA also exposes an API called NVML which is built on smi [documentation].
As previously mentioned, these industry standards, rely on software-based methodologies that approximate energy consumption. While software approximations are useful and get close to the real number, they are not direct measurements and therefore may not capture the complete picture of actual energy usage. This becomes clear looking into NVIDIA’S SMI toolkit.
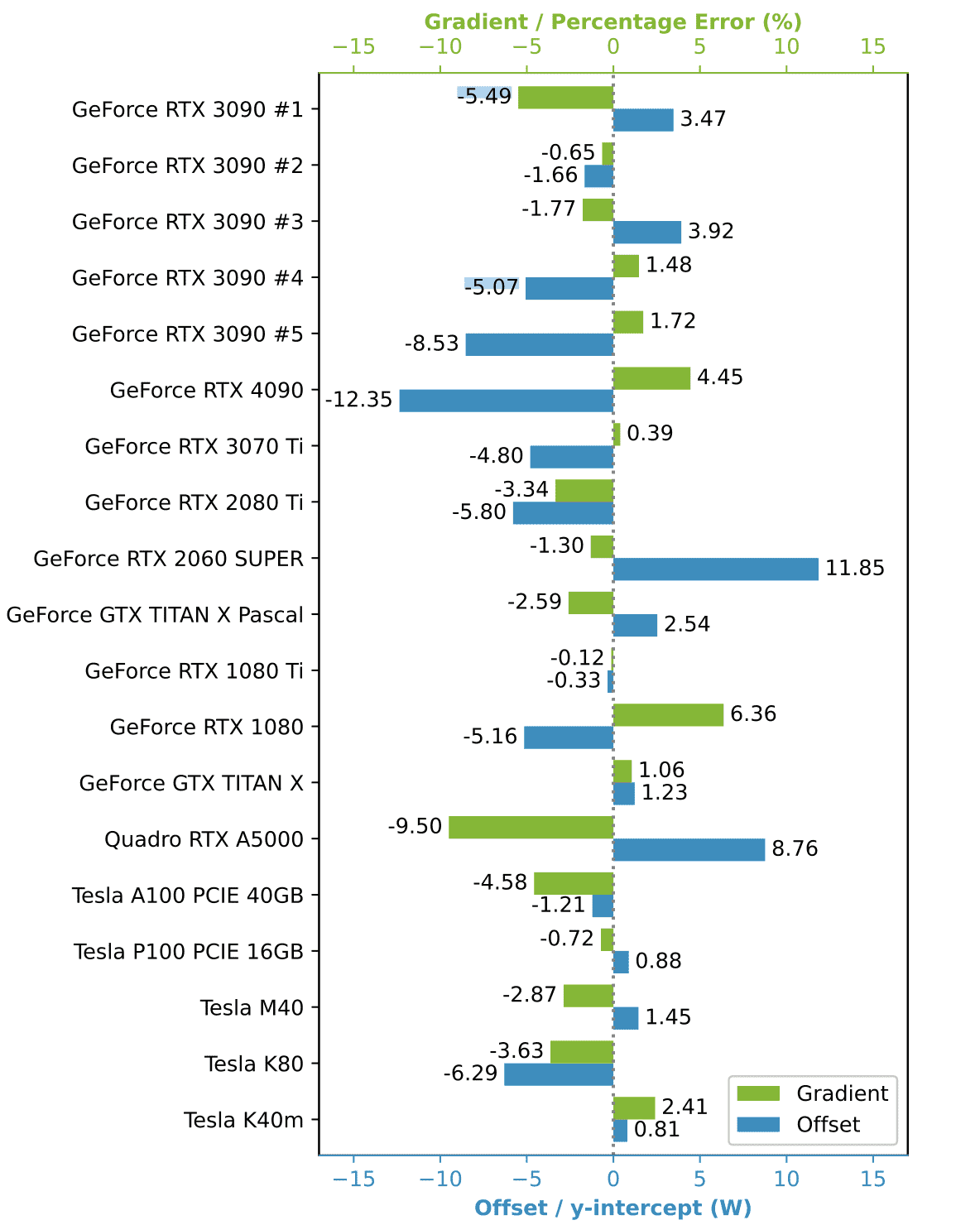
A study from March 2024 examined the accuracy of NVIDIA's nvidia-smi tool in measuring energy consumption [source]. The chart provided illustrates the need for distinct offset calibrations for each GPU model to adjust energy consumption readings accurately. Additionally, a gradient is shown for each model, indicating a significant inherent measurement error that results in either overestimation or underestimation of energy use. This demonstrates that although it is feasible to obtain precise energy metrics based on software approximations, the collection of such metrics is challenging. Moreover, layers that rely on these measurements will be able to operate with measurement errors generated in preceding layers.
In addition to energy-related metrics, resource metrics such as lifetime, expected lifetime, embodies natural resources and effective degree of utilization (among others) will also play a role in the future. Plus, a focus on the usability of hardware for future software iterations so that old hardware remains usable with new software.
Operating System — Energy Management in Operating Systems on Linux
In general, operating systems (OS) facilitate the interaction between hardware capabilities and application requirements. As with the previous hardware layer, there are different vendors. However, there is a larger focus on UNIX and Linux-based systems, since they are most spread in datacenters. The OS orchestrates the management of processes and file systems, oversees memory allocation, and regulates access to hardware resources, ensuring efficient operation and security. With this, operating systems are responsible for configuring how to leverage hardware resources best, which influences energy usage. It is also responsible for managing thermal performance, which is caused by energy consumption (Dynamic Thermal Power Management (DTOM)). The Linux Kernel has detailed documentation about their power management features [documentation].
Linux power management employs two principal strategies—static and dynamic—each designed to optimize energy efficiency while addressing different operational needs:
- Static Power Management: Establishes a fixed power configuration from the start, such as disabling unused devices, that does not adjust according to the system's workload. While this approach ensures a consistent power usage profile, it may not be as efficient under varying operational demands due to its lack of responsiveness to changes in system activity.
- Dynamic Power Management: A more sophisticated approach that enables the operating system to dynamically respond to the system's needs. This involves adjusting the power states of hardware devices (e.g., ON, OFF, STANDBY, SLEEP, HIBERNATE) and modifying CPU performance characteristics through techniques like Dynamic Voltage and Frequency Scaling (DVFS). It also includes selectively enabling or disabling hardware components, such as CPU cores, based on real-time workload analysis. The implementation of ACPI, alongside other dynamic management techniques, allows Linux to adapt its power management policies to the current state and demands of the system, optimizing energy usage, performance, and Quality of Service (QoS)
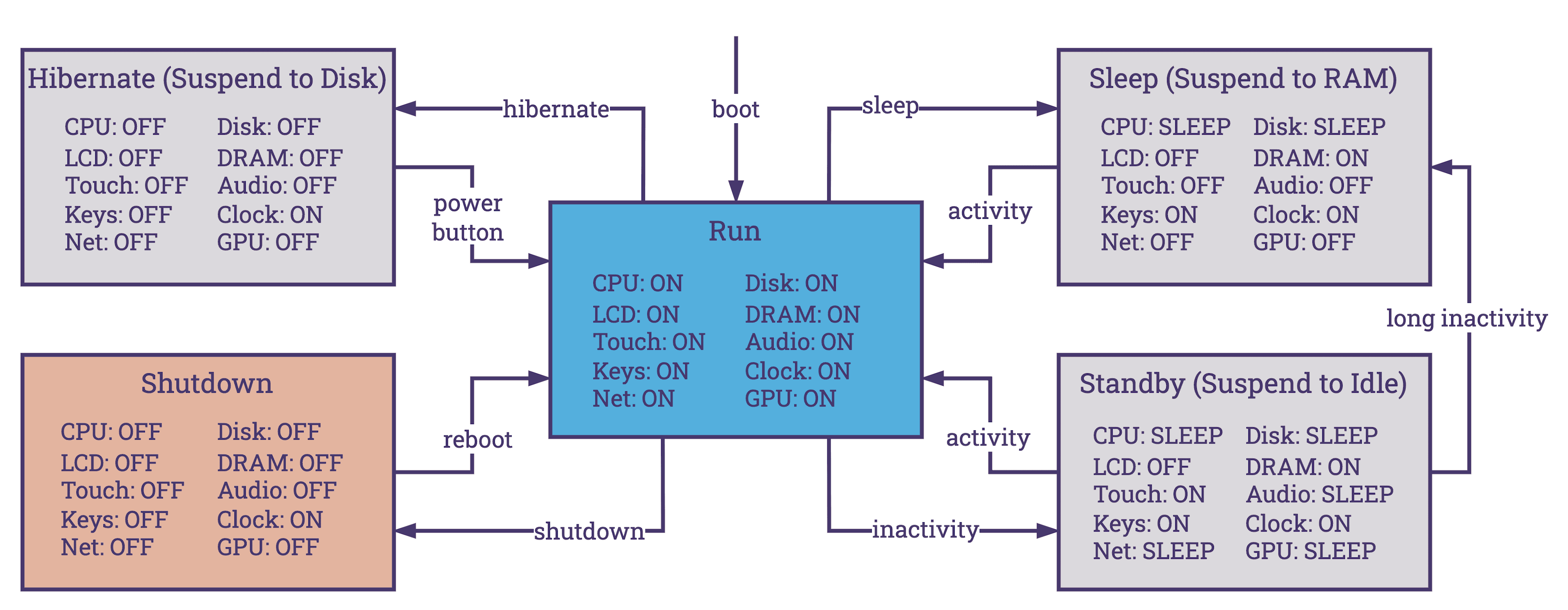
There are different ways to interact with energy management settings on Linux:
- System Interfaces: Linux exposes detailed system and hardware information, as well as control interfaces, through special file systems such as
/sysand/proc. These directories allow users and applications to query system metrics and adjust settings related to power management. For example,/sys/devices/system/cpu/cpu*/cpufreq/provides access to CPU frequency scaling settings, enabling control over the power consumption of CPU cores. - Diagnostic Tools: For real-time monitoring and analysis of system performance and power usage, Linux offers utilities like
topandhtop, which display process-level statistics including CPU and memory usage.powertopis specifically tailored for power consumption analysis. Additionally,cpufreq-infoprovides detailed information about the CPU frequency scaling, including available governors (different strategies when it comes to CPU frequency scaling) and current frequency settings. These tools are great for identifying power-hungry processes and fine-tuning system performance and energy efficiency. - Perf: Linux supports “perf events”, a powerful performance analyzing tool set that includes energy-aware profiling capabilities.
perfcan monitor a wide range of hardware and software events, offering insights into system behavior that can be leveraged to optimize power usage further. Perf events will be mentioned again in the next article when it comes to exploring the concept of using eBPF to enhance energy consumption monitoring.
Userland
At the application level, we can split the landscape in different ways. One option to look at the landscape would be to categorize it into two main types of applications: those that gather data about energy and those that use the data gathered. Alongside these applications, methodologies exist that define APIs, standards, and patterns that help us connect our services better.
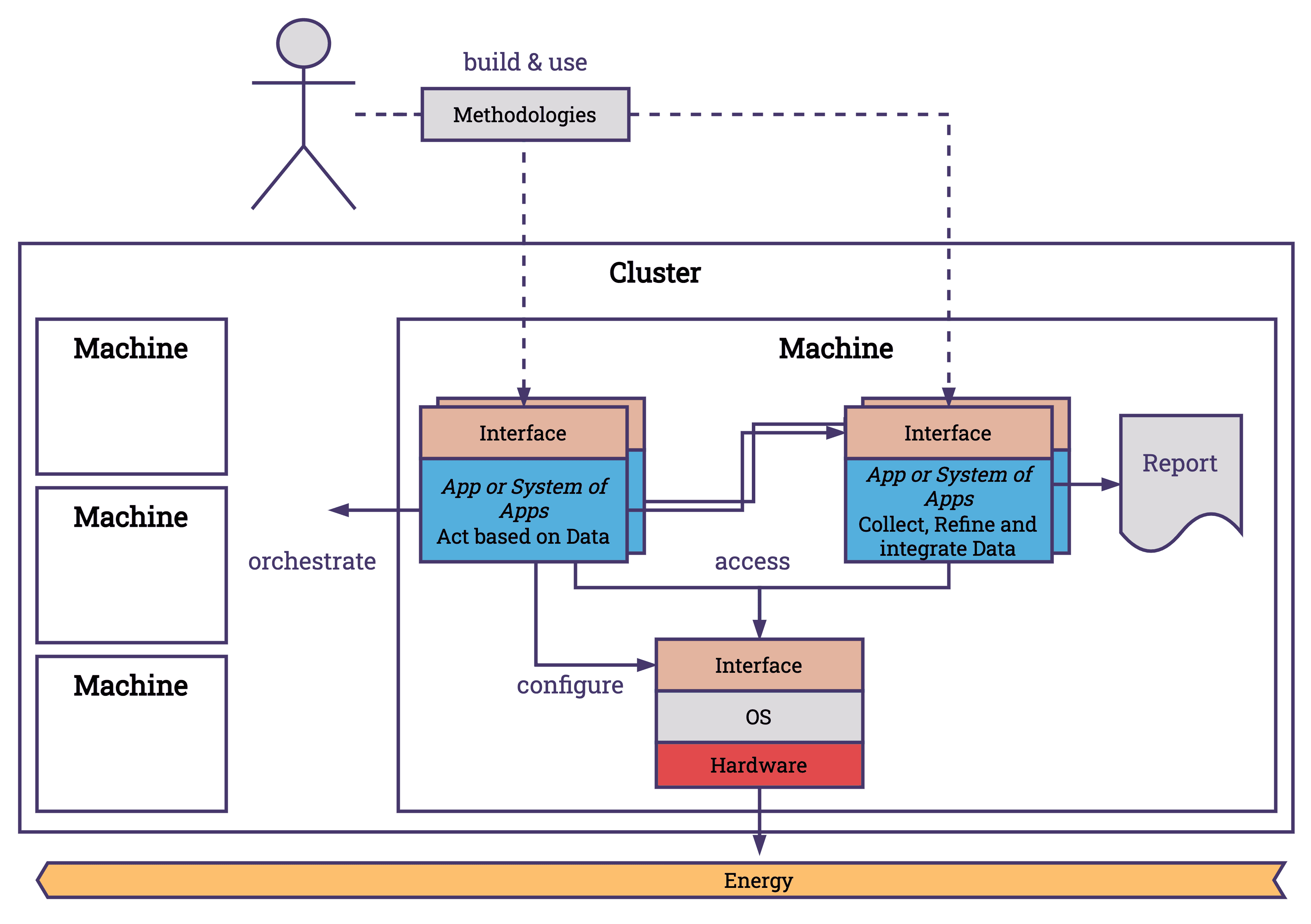
- Methodologies: These are the frameworks and approaches that define how applications are developed, including the APIs that facilitate communication between different software components.
- Applications that Collect Data: These applications or systems of applications focus on gathering information from various endpoints. A common use case is to collect the energy consumption of the system and estimate the carbon footprint based on the location and the energy mix. Collecting data, refining the data and creating higher value data is the target for applications in this category. As an example, the project Scaphandre integrates different APIs like RAPL to gather a comprehensive overview of energy metrics. These metrics are refined and exposed in different formats over a digestible endpoint, which makes integration with other projects like Prometheus and Grafana easier.
- Applications that Act Based on Data: This category includes applications that process and utilize the collected data to make automated decisions, optimize operations, and improve energy efficiency. Since the OS takes the heavy load of mediating energy consumption of applications, this obligation is already taken care of and does not need to be fulfilled by applications. It is possible to configure the OS over applications; however, I have not seen plenty of projects do that. Therefore, applications that are making decisions are usually designed for another abstraction layer that is unreachable of the OS — the cloud.
Cloud & Cluster
In the cloud, our focus shifts towards the orchestration of applications across numerous machines. At this level, our concerns include scalability, resiliency, and latency, among other factors. To efficiently allocate hardware resources among various applications, we employ various virtualization techniques. This approach allows for the virtualization of components such as CPUs, storage, and network resources (et al.). We utilize technologies such as Virtual Machines, Containers, and emerging technologies like WebAssembly (WASM) to provide isolated environments for hosting applications on these machines. Virtualization is performed at the operating system and user level and is leveraged heavily by the cloud. Virtualization is great because it allows us to share and use resources better, which in turn improves utilization and reduces energy consumption.
[SIDE NOTE] To effectively manage large numbers of computers—ranging from hundreds to thousands—we depend on a robust data center infrastructure. Machines often integrate with standardized interfaces such as the Intelligent Platform Management Interface (IPMI) and Data Center Infrastructure Management (DCIM) standards. These standards assist in configuring energy consumption and in monitoring hardware health and managing system events across different platforms, independently of the operating system. This capability enables remote management of power states, supporting actions like rebooting or shutting down systems to conserve energy under certain conditions.
Kubernetes, along with other orchestrators, simplifies these complexities within the cloud environment. You may have heard that Kubernetes can be considered to be the operating system of the cloud. Kubernetes facilitates the interaction between infrastructure capabilities and platform requirements. Like Linux, Kubernetes has developed practices and interfaces that have evolved into standards, building an ecosystem of tools that extend its functionalities. These cloud operating systems efficiently distribute applications across available resources, scale applications in response to fluctuating demands, manage service connectivity, and configure resources to match an expected state, among other tasks. How does this relate to energy consumption?
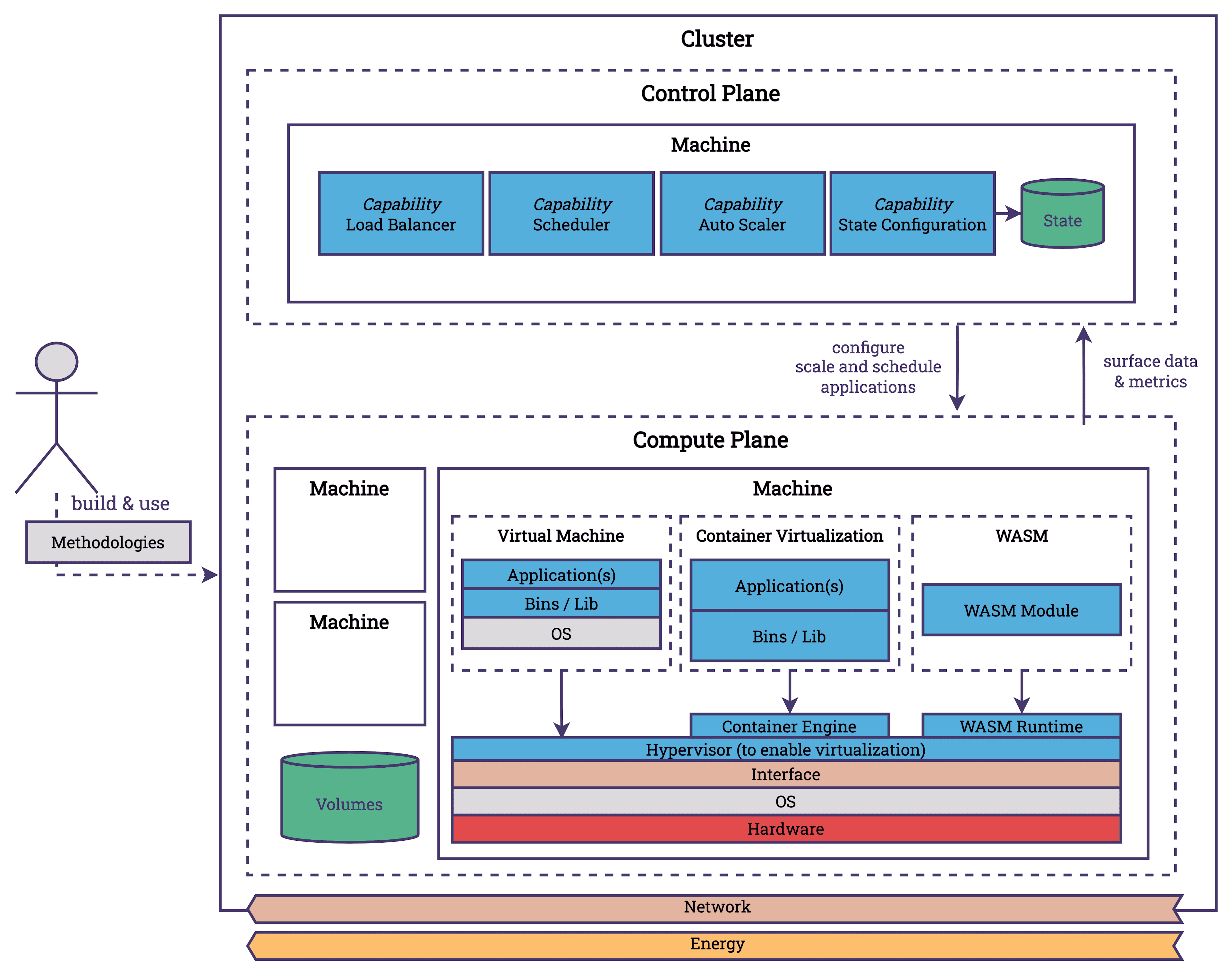
- Scaling: Scaling is fundamentally about adjusting the capacity of applications to meet current demands, which plays a significant role in terms of energy consumption. Efficient scaling minimizes unnecessary resource usage, thereby conserving energy. For instance, KEDA allows scaling deployments to 0, minimizing the resource consumption. Or Karpenter which allows Kubernetes to scale not just pods but also nodes.
- Scheduling: Scheduling involves allocating tasks or applications to the most appropriate resources available. It impacts energy consumption by ensuring that workloads are placed on nodes in a way that maximizes resource utilization and minimizes waste. Applications that communicate a lot with each other can be placed next to each other, or resource intensive tasks can be performed when an excess amount of energy is available (which happens with renewables). Scheduling is also about shipping new versions of applications when it is required and not all the time. Deploying new versions of software every day should not be necessary (for the vast majority of systems). KubeGreen would be an example project that focuses on energy aware scheduling.
- Configuration and Tuning: This aspect is about the adjustment of system settings and application parameters to achieve optimal performance and resource usage. It is about setting up the nodes with applications, so the control plane is aware of key metrics, that applications deployed on the machine have a minimal footprint. Reducing the container image size, using ARM instead of x86, doing smart updates of dependencies.
Due to the distributed nature of cloud systems, an important consideration in scaling and scheduling is networking. The very existence of distributed systems is to tackle use cases that are not feasible without the combined effort of interconnected machines. Understanding communication patterns is crucial when scaling and scheduling services to ensure efficiency and effectiveness.
In the next blog, we will explore the limitations of current practices in energy measurement in the cloud and discuss potential improvements.